欢迎访问K8凯发·国际!




|凯发娱乐平台直属总代DeepSeek“开源五连发”进行时英伟达隔空联动“芯片”或将面临被限
发布时间:
2025/06
日前,黄仁勋也首次回应DeepSeek冲击■◆◆,称赞其开源推理模型所带来的能量“令人无比兴奋”,但投资人★★■◆“判断错误”了,误以为这对英伟达算力市场是不利的,DeepSeek不仅不会终结AI计算需求,反而会扩大并加速市场对更高效AI模型的追求★■◆■,从而推动整个行业的发展◆◆。
有趣的是■★■,在DeepSeek开源周连发两弹吸引广大开发者注意的同时◆★★,英伟达通过梦幻联动的方式,展示了最强AI算力硬件和DeepSeek开源技术相结合所能实现的全新可能性★★■■。
2. FlashMLA针对可变长度序列进行了优化◆★★◆,这是自然语言处理(NLP)任务的一项关键功能,其中输入数据(如句子或文档)的长度可能有很大差异。这种灵活性使其成为现实世界的AI应用的理想选择◆★◆◆,例如聊天机器人◆★★★★、翻译系统和文本生成,其中序列并不统一。

当然最值得称赞的是,这么宝贵的技术经验具备★◆“开源可用性”,它是一种成熟且经过测试的解决方案◆◆★■★,能够投入实际部署,使全球开发人员和研究人员能够访问◆◆、修改和将这项技术集成到各自项目中做更多创新。
而DeepSeek团队通过开源这些技术细节,也正在有力反驳一些质疑者提出的■★★◆◆“他们在训练程序上撒谎”的说法★■★★■。
但面对DeepSeek的异军突起和出乎意料的全球影响力,开发DeepSeek模型所依托的NVIDIA中国★◆“芯片”或将面临被美国进一步限制的风险。
特朗普政府就限制向中国出口这些芯片的讨论还处于非常早期,白宫目前没有回应置评,英伟达则在一份声明中表示■★:“已准备好与政府协商◆◆★★◆,以保障其在AI领域的持续发展★◆★◆”。
业内预测◆■★■◆,接下来几天可能会陆续开源数据处理管道、AI训练优化工具、机器学习模型等相关技术,让行业对GPU算力的使用更加高效,便于开发者们搭建速度更快■◆★■★■、性能更强★■、可扩展的AI模型。
DeepEP被开发者们视为是MoE模型训练和推理的新晋颠覆者,对接下来要开源的技术更加充满期待■◆。

AI界“源神”DeepSeek本周正在将自己所积累的实战技术干货一点点释放给全球开发者★★■◆,对AI模型和算力行业的下一步发展产生深刻影响。
今天★◆,DeepSeek推出DeepEP——第一个用于MoE模型训练和推理的开EP通信库,在NVIDIA H800上完成测试,效果出色,能以最大限度地提高计算吞吐量、减少延迟凯发娱乐平台直属总代。
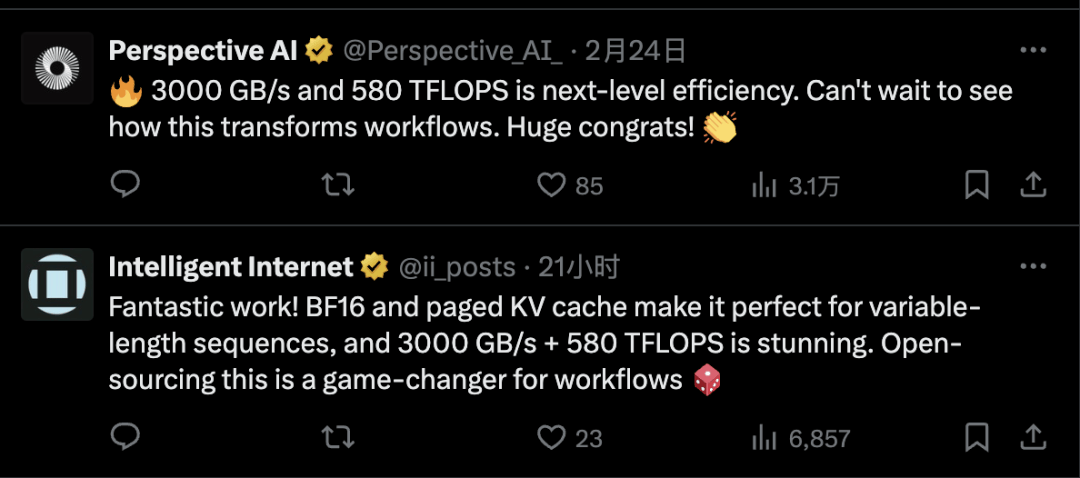
该内核实现了卓越的性能指标:3000 GB/s内存带宽(内存绑定性能),实现快速的数据访问和传输★■★★◆;580 TFLOPS计算性能(计算绑定性能),为AI工作负载提供了更高的计算吞吐量。
4◆■◆◆◆■. FlashMLA支持BF16(Brain Float 16)精度,这是一种紧凑的数字格式,可平衡模型精度和计算效率。与FP32(32 位浮点)等更高精度的格式相比,BF16可减少内存使用量并加快计算速度,同时保持大多数AI任务所需的足够精度。
而对于■■◆“DeepEP”,开发者们表示它就像一个先进的高速公路系统■★■◆◆■。想象一条繁忙的高速公路,其中汽车代表数据★★◆★,城市象征计算机组件,如果没有精心规划的道路和交通规则◆■,拥堵和延误将不可避免。
路透社独家消息称,随着中国大范围接入DeepSeek的AI模型,英伟达的H20芯片订单正呈现需求激增,例如百度和字节跳动等大厂加大了H20的订单。此外,医疗和教育等行业的小型企业也在购买配备DeepSeek模型和H20芯片的AI服务器。
3. 内核使用分页的KV缓存,块大小为64,这提高了内存效率并减少了解码期间的延迟。这对于LLM尤其有益■■◆★■,因为内存限制可能会成为性能的瓶颈。
DeepSeek连续开源推出“FlashMLA”和“DeepEP”之后,在开发者社区引起了积极响应,有网友预测,第五天可能将是一条以开源方式通往AGI的关键路径。
彭博社消息称,特朗普政府正在制定更为严厉的美国半导体限制措施,并向主要盟友施压来遏制中国AI崛起反超◆■★◆★,相关政府官员最近会见了日本和荷兰同行,讨论限制东京电子有限公司■★★◆■、阿斯麦控股公司等工程师在中国维护半导体设备的问题。
GPU为AI模型提供动力,但其效率取决于其处理和交换数据的能力★★◆■◆,DeepEP集成了专用GPU内核 ,可最大程度提高处理速度■◆,将等待时间缩短至几乎为零◆■。
【2025免费新年礼】:了解最新科技趋势分析★◆◆◆、行业内部的独家见解★◆、定期的互动讨论和知识分享、与行业专家的直接面对面交流的机会,领取100份AI科技商业研报合集,加群共同探讨与成长——
5◆■. 支持更大规模的AI模型。通过利用闪存和优化数据传输,FlashMLA可以高效地推理超出GPU DRAM容量的大型语言模型。这意味着FlashMLA可以帮助在Hopper GPU上部署和运行大量AI模型,而无需昂贵的硬件升级★★■■■◆。
几周前,DeepSeek对美国科技股造成冲击★◆★,一度让英伟达市值蒸发近6000亿美元,规模创下美股史上最大,但随着DeepSeek对全球AI开发者的赋能◆★★■■◆,更加广泛的AI算力需求逐渐增长,为英伟达带来了潜在收益。
DeepEP的作用就像是一个先进“调度指挥官”,实现了目前最高通勤效率,怎么做到的呢?


在各行业为DeepSeek的成就欢呼点赞纷纷接入的同时★■,破解算力限制风险冲刺世界最领先AI模型的步伐也要加快了■■★◆◆,中美之间的AI竞赛还远未结束◆■★◆。
在混合专家(MoE)模型中,每个专家都必须与其他所有专家交换数据,DeepEP使这一过程没有瓶颈,就像给每辆车提供自己的高速车道一样。
第一天,DeepSeek率先开源了FlashMLA◆★■■■★,这是一款基于NVIDIA Hopper GPU开发的高效MLA解码内核凯发娱乐平台直属总代★■★◆■◆,针对可变长度序列进行了优化■★◆■,用于减少计算开销,同时保持出色性能,目前已投入生产。

由于美国的出口管制,H20是英伟达专门面向中国市场推出的一款芯片◆◆■■◆★,与其旗舰芯片H100相比,综合算力降低了约80%,另外,DeepSeek训练所使用的H800也是英伟达对H100的调整版本,在数据传输和双精度计算等方面均有所削弱,只是没人能预料到DeepSeek会把算力运用的如此充分。
利用Hopper架构的H100集成了800亿个晶体管,而Blackwell架构GPU具有2080亿个晶体管■★★■★,整体AI性能比Hopper架构提高了5倍,在FP4精度下,推理性能可提高30倍左右。
DeepEP利用NVIDIA的高速连接技术NVLink来加速这一过程,节点间通信发生在不同的计算机或芯片之间,类似于城市间行驶的汽车◆■■★;利用RDMA在机器之间直接传输数据,最大限度地减少延迟并优化性能◆■★★。
此动态展现出了英伟达对DeepSeek开源技术的极高重视。Blackwell架构是比DeepSeek开源周提到的NVIDIA Hopper GPU架构更先进的新一代架构■★★■◆◆,专为运行万亿级参数的AI模型而设计。
此外■■,DeepEP允许开发人员在GPU之间动态分配计算任务★■◆★◆,无缝适应不同的硬件配置,通过优化各个层面的数据流,确保即使是最复杂★■■★◆■、最分散的AI系统也能平稳高效地运行。
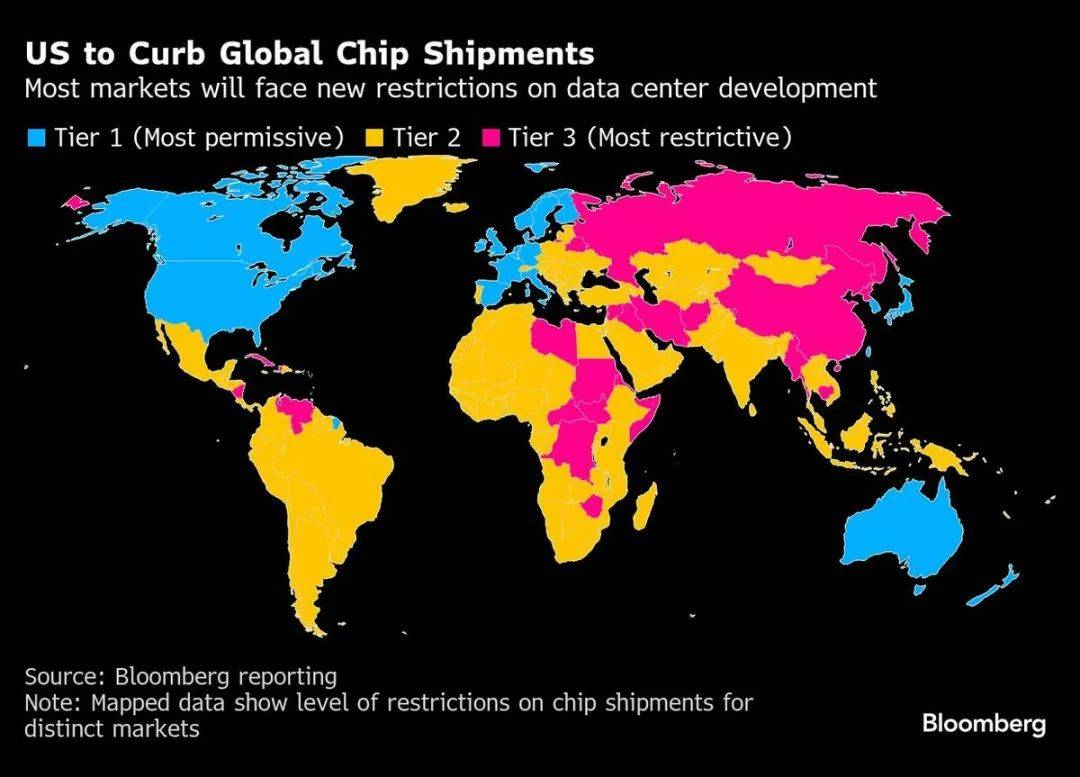
拜登和特朗普政府交接之前还颁发了一系列限制向中国出口人工智能芯片的措施,其中比较受关注的是《人工智能扩散框架》,该框架计划于2025年5月开始实施,其中制定了适用于先进计算集成电路的出口★■★、再出口和国内转让的三级许可框架,中国是被限制最严格的国家之一■■。
据路透社独家报道,特朗普政府正在考虑对向中国出售的H20、H800等芯片实施新一轮限制★◆■★★,消息人士称DeepSeek或是主要诱因。
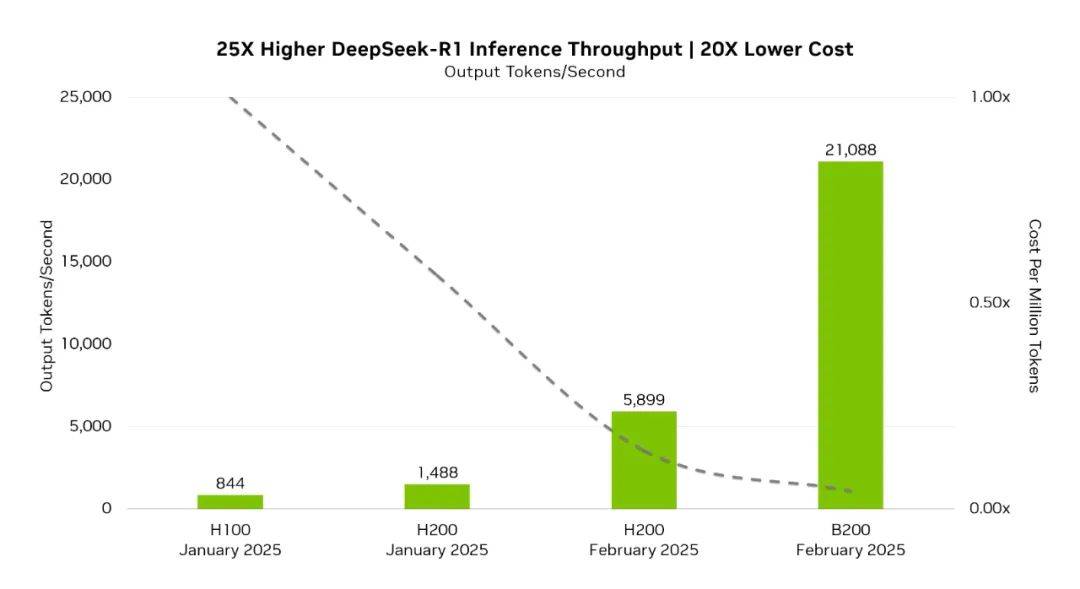
今天,英伟达紧跟DeepSeek节奏推出针对Blackwell架构的DeepSeek-R1优化方案★★■★■■,与仅仅四周前的英伟达H100相比,该方案能使每生成一个token的成本降低至原来的二十分之一,但同时推理吞吐量提高了25倍。
关键词
我们的产品
活牛进场严格按照检验流程操作,对所有肉牛进场前进行血清检测瘦肉精,合格后进入待宰圈静养,静养后进行屠宰。屠宰过程全部按照清真工艺要求和屠宰操作规程进行,所有牛肉产品检测合格后才准出厂。
关注我们
